Node-上之基本知识
Node-上之基本知识
一、入门
1.1 什么是Node
- Node.js 是什么?
- JavaScript 运行环境
- 既不是语言,也不是框架,它是一个平台
- Node.js 中的 JavaScript
- 没有 BOM、DOM。
- EcmaScript 基本的 JavaScript 语言部分。
- 在 Node 中为 JavaScript 提供了一些服务器级别的 API。
- 文件操作的能力
- http 服务的能力
1.2 使用其操作文件
注意:浏览器中的 JavaScript 是没有文件操作的能力的,但是 Node 中的 JavaScript 具有文件操作的能力。
使用 node 来操作文件有几步:
- 使用 require 方法加载 fs 核心模块。
- 读取文件。
- 处理回调函数返回的数据。
- fs 是 file-system 的简写,就是文件系统的意思。
- 在 Node 中如果想要进行文件操作,就必须引入 fs 这个核心模块
- 在 fs 这个核心模块中,就提供了所有的文件操作相关的 API。例如:fs.readFile 就是用来读取文件的。
- 具体的其他方法可以查看其用户文档。Node用户文档
(1)读文件
下面的代码示例读取 data 文件夹里的 a.txt 文件,回调函数会返回两个参数——error 和 data。
如果读取成功,error 为 null ,data 为十六进制的数据,可以使用
toString()方法来转换成字符串。如果读取失败,error 为 错误对象,而 data 为 undefined 。我们可以通过第 6 ~ 10 行来判断是否有错误发生。
// 1. 使用 require 方法加载 fs 核心模块
var fs = require('fs')
fs.readFile('./data/a.txt', function (error, data) {
// 在这里就可以通过判断 error 来确认是否有错误发生
if (error) {
console.log('读取文件失败了')
} else {
console.log(data.toString())
}
})
(2)写文件
写文件使用的是 writeFile() 方法。第一个参数:文件路径;第二个参数:文件内容;第三个参数:回调函数。
如果读取成功,error 为 null ,如果读取失败,error 为错误对象。
// 1. 使用 require 方法加载 fs 核心模块
var fs = require('fs')
fs.writeFile(
'./data/你好.md',
'大家好,给大家介绍一下,我是Node.js',
function (error) {
if (error) {
console.log('写入失败')
} else {
console.log('写入成功了')
}
}
)
1.3 使用其创建服务器
在 Node 中专门提供了一个核心模块:http,我们可以使用其非常轻松的构建一个 Web 服务器。
我们首先需要简单地知道服务器的作用:
- 接收请求。
- 处理请求。
- 发送请求——反馈信息。
(1)初步使用
第 2 行:首先第一步,加载 http 核心模块。
第 6 行:使用
createServer()方法创建一个服务器,第 10 行:为服务器绑定请求监听。第一个参数为触发请求所需的类型,第二个参数为接收到请求触发事件后执行的操作。
第 15 行:开启服务器。第一个参数为服务器所占用的端口号,第二个参数为服务器启动后的操作。
// 1. 加载 http 核心模块
var http = require('http')
// 2. 使用 http.createServer() 方法创建一个 Web 服务器
// 返回一个 Server 实例
var server = http.createServer()
// 3. 注册 request 请求事件
// 当客户端请求过来,就会自动触发服务器的 request 请求事件,然后执行第二个参数:回调处理函数
server.on('request', function () {
console.log('收到客户端的请求了')
})
// 4. 绑定端口号,启动服务器
server.listen(3000, function () {
console.log('服务器启动成功了,可以通过 http://127.0.0.1:3000/ 来进行访问')
})
(2)使用两个基本对象
上面第 10 行中的回调函数,可以选择使用两个对象——request 和 response
request:请求对象,可以知道发送请求的基本信息。request.url:获取到请求的路径,这个路径这是请求路径不是完整路径,例如,“ /js/jquery.js ” 。request.socket.remoteAddress:获取到请求的 IP 地址。request.socket.remotePort:获取到请求的端口号。
response:响应对象,可以发送响应到客户端。response.write("字符串" | 二进制数据):发送字符串或者二进制数据到客户端,在结束发送时需要使用end()方法。response.end( ["字符串" | 二进制数据] ):无参数时代表结束发送请求;有参数时代表发送参数的字符串或者二进制数据后结束发送。
1.4 根据请求路径返回不同内容
我们可以使用上面的方法和属性,做出根据请求的路径然后返回不同内容的功能。
- 路径为 “ / ” 时,返回 “ index page ” 。
- 路径为 “ /login ” 时,返回 “ login page ” 。
- 路径为 “ /products ” 时,返回数组对象的字符串 。
- 注意:响应内容只能是二进制数据或者字符串。
server.on('request', function (request, response) {
var url = request.url
if (url === '/') {
response.end('index page')
} else if (url === '/login') {
response.end('login page')
} else if (url === '/products') {
var products = [{
name: '苹果 X',
price: 8888
},
{
name: '菠萝 X',
price: 5000
},
{
name: '小辣椒 X',
price: 1999
}
]
// 响应内容只能是二进制数据或者字符串
response.end(JSON.stringify(products))
} else {
response.end('404 Not Found.')
}
})
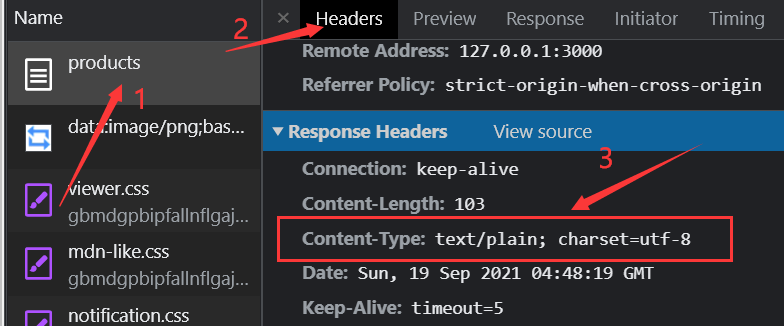
返回的内容如下图:

很明显 JSON 字符串乱码了,因为在没有指定编码时,浏览器会根据操作系统的默认字符集来编码。而中文操作系统默认是 GBK。
解决乱码问题有两种方式:
- 改变浏览器的编码
- 最新版谷歌浏览器已经将这个功能移出,需要额外安装插件。
- 设置响应头部的
Content-Type。Content-Type就是用来告知客户端的所发数据内容是什么类型的。- 具体的可以查表:菜鸟教程——HTTP content-type
所以上面的代码添加第 5 行来设置响应头,因为我们传的字符串也是 JSON 类型字符串所以也可以使用 application/json:
server.on('request', function (request, response) {
var url = request.url
//response.setHeader('Content-Type', 'application/json; charset=utf-8')
response.setHeader('Content-Type', 'text/plain; charset=utf-8')
if (url === '/') {
response.end('index page')
} else if (url === '/login') {
response.end('login page')
} else if (url === '/products') {
var products = [{
name: '苹果 X',
price: 8888
},
{
name: '菠萝 X',
price: 5000
},
{
name: '小辣椒 X',
price: 1999
}
]
// 响应内容只能是二进制数据或者字符串
response.end(JSON.stringify(products))
} else {
response.end('404 Not Found.')
}
})
我们可以使用浏览器来看当前的响应头是哪种类型,如下图所示。
二、将服务器和文件操作结合
我们通常不只是发送字符串信息,而且要发送网页到客户端。所以需要读网页的文件。
2.1 初步示例
下面的代码中,当访问路径为 " / " 时,发送 index.html 文件到客户端。当访问路径为 " /picture " 时,发送 一张图片到客户端。
server.on('request', function (req, res) {
var url = req.url
if (url === '/') {
// 我们要发送的还是在文件中的内容
fs.readFile('./resource/index.html', function (err, data) {
if (err) {
res.setHeader('Content-Type', 'text/plain; charset=utf-8')
res.end('文件读取失败,请稍后重试!')
} else {
res.setHeader('Content-Type', 'text/html; charset=utf-8')
res.end(data)
}
})
} else if (url === '/picture') {
// url:统一资源定位符
// 一个 url 最终其实是要对应到一个资源的
fs.readFile('./resource/ab2.jpg', function (err, data) {
if (err) {
res.setHeader('Content-Type', 'text/plain; charset=utf-8')
res.end('文件读取失败,请稍后重试!')
} else {
// 图片就不需要指定编码了,因为我们常说的编码一般指的是:字符编码
res.setHeader('Content-Type', 'image/jpeg')
res.end(data)
}
})
}
})
2.2 使用字符串拼接实现tomcat功能
Tomcat 里有一个功能,就是可以在服务器里查看并操作文件或者目录。
这里需要实现这个功能。
使用字符串实现
下面是一个模板网页,我们需要在这个网页添加数据。
<body>
<div id="listingParsingErrorBox">糟糕!Google Chrome无法解读服务器所发送的数据。请<a href="http://code.google.com/p/chromium/issues/entry">报告错误</a>,并附上<a href="LOCATION">原始列表</a>。</div>
<h1 id="header">D:\Movie\www\ 的索引</h1>
<div id="parentDirLinkBox" style="display:none">
<a id="parentDirLink" class="icon up">
<span id="parentDirText">[上级目录]</span>
</a>
</div>
<table>
<thead>
<tr class="header" id="theader">
<th onclick="javascript:sortTable(0);">名称</th>
<th class="detailsColumn" onclick="javascript:sortTable(1);">
大小
</th>
<th class="detailsColumn" onclick="javascript:sortTable(2);">
修改日期
</th>
</tr>
</thead>
<tbody id="tbody">^_^</tbody>
</table>
</body>
我们实现这个功能需要以下几步:
第 4 行:读取模板网页。
第 14 行: 获取到指定目录下的所有文件。需要使用到
fs.readdir()方法,该方法的回调函数会传进两个参数,error 为错误对象,files 为文件名称数组。第 21 行:使用文件名称数组的数据来拼接字符串,生成插入模板网页的数据。
第 33 、34 行:使用
replace()方法,将模板标识符替换成数据。
var wwwDir = 'D:/历史学习/源码_课件/jQueryTest'
server.on('request', function (req, res) {
var url = req.url
fs.readFile('./template.html', function (err, data) {
if (err) {
return res.end('404 Not Found.')
}
// 1. 如何得到 wwwDir 目录列表中的文件名和目录名
// fs.readdir
// 2. 如何将得到的文件名和目录名替换到 template.html 中
// 2.1 在 template.html 中需要替换的位置预留一个特殊的标记(就像以前使用模板引擎的标记一样)
// 2.2 根据 files 生成需要的 HTML 内容
// 只要你做了这两件事儿,那这个问题就解决了
fs.readdir(wwwDir, function (err, files) {
if (err) {
return res.end('Can not find www dir.')
}
// 2.1 生成需要替换的内容
var content = ''
files.forEach(function (item) {
// 在 EcmaScript 6 的 ` 字符串中,可以使用 ${} 来引用变量
content += `
<tr>
<td data-value="apple/"><a class="icon dir" href="/D:/Movie/www/apple/">${item}/</a></td>
<td class="detailsColumn" data-value="0"></td>
<td class="detailsColumn" data-value="1509589967">2017/11/2 上午10:32:47</td>
</tr>
`
})
// 2.3 替换
data = data.toString()
data = data.replace('^_^', content)
// 3. 发送解析替换过后的响应数据
res.end(data)
})
})
})
2.3 使用模板语言实现tomcat功能
我们使用的模板语言是 ART-TEMPLATE
(1)ART-TEMPLATE介绍
在 Node 中使用 art-template 模板引擎,模板引擎最早就是诞生于服务器领域,后来才发展到了前端。
使用步骤:
安装 npm install art-template
在需要使用的文件模块中加载 art-template
- 只需要使用 require 方法加载就可以了:require('art-template')。
- 参数中的 art-template 就是你下载的包的名字
- 也就是说你 isntall 的名字是什么,则你 require 中的就是什么
查文档,使用模板引擎的 API
(2)模板的基本语法
1. 输出:
+ `{{ 属性名 }}`
+ 例如 `{{value}}` 、 `{{data.key}}`
2. 条件
+ `{{if 条件}} ... {{/if}}`
+ `{{if 条件1}} ... {{else if 条件2}} ... {{/if}}`
3. 循环
+ `{{each target}} {{$index}} {{$value}} {{/each}}`
+ 我们也可以给 `$index` 和 `$value` 取别名。
+ `{{each target val key}} {{ key }} {{ val }} {{/each}}`
4. 变量
+ `{{set temp = data.sub.content}}`
我们可以使用原始语法来使用模板。
我们可以使用原始语法来使用模板。
// 下面为模板的原始语法
// 1. 输出<%= value %><%= data.key %>
// 2. 条件<% if (value) { %> ... <% } %><% if (v1) { %> ... <% } else if (v2) { %> ... <% } %>
// 3. 循环<% for(var i = 0; i < target.length; i++){ %> <%= i %> <%= target[i] %><% } %>
// 4. 变量<% var temp = data.sub.content; %>
(3)在浏览器中使用模板
先介绍一下在浏览器中如何使用模板。
- 引入模板引擎所需要的文件。``
- 在 srcipt 标签中写入代码,需要指明 id 和 type 属性。
<script type="text/template" id="tpl">
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<p>大家好,我叫:{{ name }}</p>
<p>我今年 {{ age }} 岁了</p>
<h1>我来自 {{ province }}</h1>
<p>我喜欢:{{each hobbies}} {{ $value }} {{/each}}</p>
</body>
</html>
</script>
- 在 普通的 srcipt 标签 中,使用
template()方法,方法里的第一个参数为需要替换的 srcipt 标签的 id 值,第二个参数为替换的数据,返回值为替换完成的字符串。
<script>
var ret = template('tpl', {
name: 'Jack',
age: 18,
province: '北京市',
hobbies: [
'写代码',
'唱歌',
'打游戏'
]
})
console.log(ret)
</script>
(4)在node中使用模板
因为 node 中没有 DOM ,所以无法得到 srcipt 的 id 值,所以我们需要使用另外一个方法。
template.render(source, data [, options] ):source:字符串,模板。data:对象。替换模板里内容的数据。options:对象。一些选项。
使用步骤:
- 读取文件内容并转换成字符串。
- 使用
render()方法,替换模板中的内容,返回的就是最终数据。
fs.readFile('./tpl.html', function (err, data) {
if (err) {
return console.log('读取文件失败了')
}
// 默认读取到的 data 是二进制数据
// 而模板引擎的 render 方法需要接收的是字符串
// 所以我们在这里需要把 data 二进制数据转为 字符串 才可以给模板引擎使用
var ret = template.render(data.toString(), {
name: 'Jack',
age: 18,
province: '北京市',
hobbies: [
'写代码',
'唱歌',
'打游戏'
],
title: '个人信息'
})
console.log(ret)
}
2.4 URL模块
(1)URL模块用法
node 提供了 URL 模块,可供我们解析网址。我们可以使用其里面的一个方法。
url.parse( urlString [, parseQueryString [, slashesDenoteHost]] ):- 旧版,现不建议使用。
urlString:字符串。要解析的 URL 字符串。parseQueryString:布尔值。是否要解析 query 属性。slashesDenoteHost:布尔值。pathname 的不同解析方式。- 返回值:解析结果对象。
而我们现在需要使用 新版的 WHATWG 网址 API:
new URL( input[, base] )- 新版,建议使用
input:要解析的绝对或相对的输入网址。 如果 input 是相对的,则需要 base。 如果 input 是绝对的,则忽略 base。base:如果 input 不是绝对的,则为要解析的基本网址。- 返回值:解析结果对象。
举一个例子:如果需要解析 http://127.0.0.1:3000/pinglun?name=张三&message=今天天气真好
则这样使用:
var obj = new URL("/pinglun?name=张三&message=今天天气真好", "http://127.0.0.1:3000")
console.log(obj)
返回的是就是有许多属性的对象。我们可以会使用到第 12 行的键值对。 其是 URLSearchParams 类型,需要使用其里面的 foreach() 方法来遍历。
URL {
href: 'http://127.0.0.1:3000/pinglun?name=%E5%BC%A0%E4%B8%89&message=%E4%BB%8A%E5%A4%A9%E5%A4%A9%E6%B0%94%E7%9C%9F%E5%A5%BD',
origin: 'http://127.0.0.1:3000',
protocol: 'http:',
username: '',
password: '',
host: '127.0.0.1:3000',
hostname: '127.0.0.1',
port: '3000',
pathname: '/pinglun',
search: '?name=%E5%BC%A0%E4%B8%89&message=%E4%BB%8A%E5%A4%A9%E5%A4%A9%E6%B0%94%E7%9C%9F%E5%A5%BD',
searchParams: URLSearchParams { 'name' => '张三', 'message' => '今天天气真好' },
hash: ''
}
遍历代码如下:
obj.forEach(function(value, key){
// 。。。。
})
(2)URI和URL
上面提到的是 URL,URL = Uniform Resource Locator 统一资源 定位符。
还有一个概念,URN,URN = Uniform Resource Name 统一资源 名称。
上面两个概念合在一起就是 URI,大写的【i】,URI = Uniform Resource Identifier 统一资源 标志符。
三个的区别:
- URL 是 注重位置 来确定一个资源的。例如根据你家的地址来确定你。
- URN 是 注重名字 来确定一个资源的。例如根据你的身份证号来确定你。
- URI :只要可以确定一个资源的,都可以称为 URI,无论使用的是什么规则。
- 但我们最多使用 URI 的里的 URL,例如 HTTP 协议,文件系统等,所以一般说 URI 都等于说 URL。
2.5 Path模块
我们一般读取文件的时候,都需要使用到 URL,如果我们要拼接 URL 时,会遇到下面的问题:
- 前面的 URL 不确定 结尾 有没有 【 \ 】反斜杠。
- 后面的 URL 不确定 开头 有没有 【 \ 】反斜杠。
如果我们手动来判断,再拼接的话,就很不方便,所以我们可以使用 path.join() 方法。
那首先先介绍 Path 模块一些基本的解析方法:
path.basename(path[, ext])- path: <string>
- ext: <string> 可选的文件扩展名
- 返回: <string> 解析后的字符串
2.6 OS模块
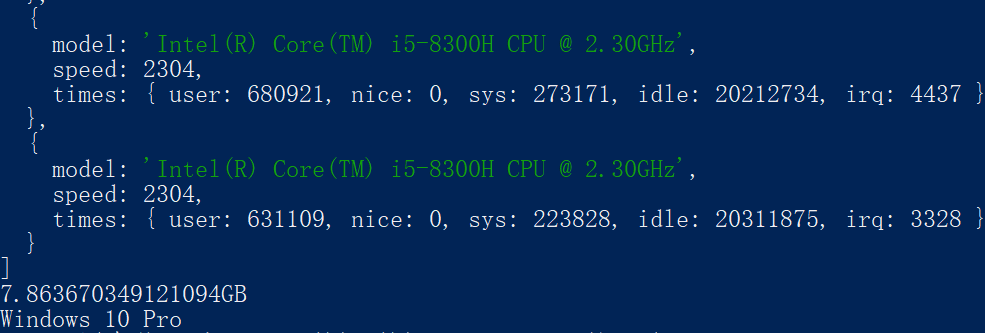
既然 node 可以读取系统的文件,那么当然也可以读取系统中的配置。
可以读取 CPU 的信息:
os.cpus()。可以读取 内存 的信息——总内存数量:
os.totalmem()。返回值为 字节,所以可以使用这句代码来变换单位成 GBos.totalmem()/1024/1024/1024。可以读取 操作系统 的信息——标识内核版本的字符串:
os.version()
结果如下:
2.7 简单实现文件管理器
结合 url 模块,我们可以实现类似 window 系统的文件管理器。根据网址来显示本地文件的目录。
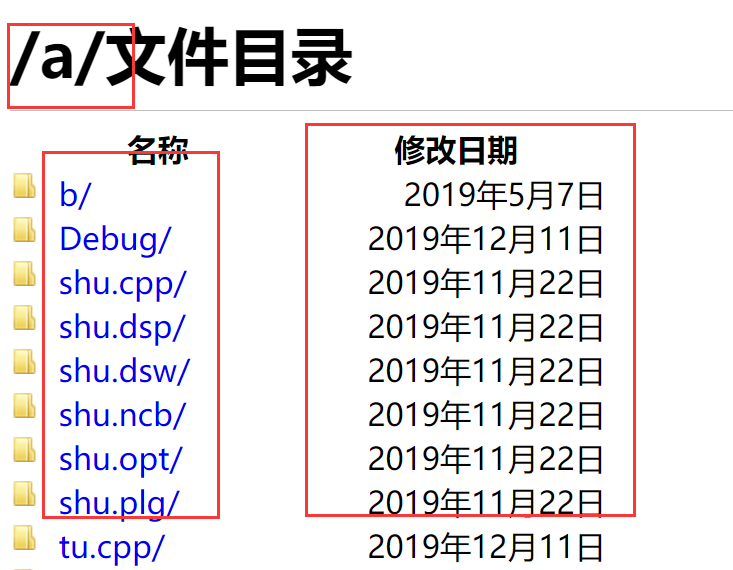
(1)页面
首先是页面布局,与上面的布局有点相似。
- 第 2 行标识当前的目录
- 第 12 ~ 26 行:显示文件和其修改日期。
<body>
<h1 id="header">{{urlPath}}文件目录</h1>
<table>
<thead>
<tr class="header" id="theader">
<th onclick="javascript:sortTable(0);">名称</th>
<th class="detailsColumn" onclick="javascript:sortTable(2);">
修改日期
</th>
</tr>
</thead>
<tbody id="tbody">
{{each files}}
<tr>
<td data-value="apple/">
<a class="icon dir" href="javascript:void(0)">
{{$value}}/
</a>
</td>
{{ set key = $index }}
<td class="detailsColumn" data-value="1509589967">
{{array[key]}}
</td>
</tr>
{{/each}}
</tbody>
</table>
</body>
其中的 Javascript 标签里的代码:
- 为每一个文件加上点击事件,当点击时发送打开该文件或文件夹的请求。
- 第 5 行:由于当访问
127.0.0.1:3000时,浏览器有时会加上 " # " ,所以需要将这个符号去掉,再进行第 6 行的网址拼接操作。
let dirs = document.getElementsByClassName('icon')
for (let i = 0; i < dirs.length; i++) {
dirs[i].addEventListener('click', function () {
let href = window.location.href.replace('#', '')
window.location.href = href + this.innerText
})
}
(2)接收客户端发送的请求
客户端发送的请求为相对路径,所以不用将前面的 " 127.0.0.1:3000 " 去除了。当我们的 uri(统一资源标识符)中有中文时,发送请求时就编码成 UTF-8 的字符序列,我们服务器接收时,就需要进行解码。
Javascript 中自带了编码解码功能,直接使用即可,如第 11 行所示。
var wwwDir = 'D:/'
server.on('request', function (req, res) {
// 1. 如果是文件,直接读取响应
// 2. 如果是目录,读取渲染目录列表
// 3. 如果目录并且有该目录中有 index.html 则直接渲染目录中的 index.html
// var urlPath = path.join(wwwDir, url)
// 这里传过来的url,如果有中文则会进行Unicode编码,
// 而要根据url找其相应的文件,需要解码成字符串
var urlPath = decodeURIComponent(req.url)
// 。。。。
(3)判断文件类型
请求如果是文件则直接在浏览器打开,如果是目录则返回目录列表。
这里读取文件的状态可以不使用同步方法,因为这个方法后面没有代码了。
回调函数中的 stats 变量为 urlPath 所指定的文件或者文件夹的状态。
我们可以根据两个方法—— isFile() 和 stats.isDirectory() 来判断该路径是文件还是文件夹。
// 根据请求的路径获取到对应的文件
fs.stat(urlPath, function (err, stats) {
// 错误提示
if (err) {
return res.end('404 Not Found.')
}
// 1. 如果是文件,直接读取响应
if (stats.isFile()) {
// 。。。。
} else if (stats.isDirectory()) {
// 。。。。 }
})
}
(4)处理是文件的情况
- 如果是文件则直接读取:
// 1. 如果是文件,直接读取响应
if (stats.isFile()) {
// 读取文件
fs.readFile(urlPath, function (err, data) {
if (err) {
return res.end('404 Not Found.')
}
res.end(data)
})
} else if (stats.isDirectory()) {
(5)处理是文件夹的情况
- 如果是文件夹则需要使用到模板网页。渲染模板网页需要的三个数据:
- 该文件夹里的所有文件的 名称。
- 该文件夹里的所有文件的 修改日期。
- 该文件夹里的 相对位置。
- 获取该文件夹里的所有文件的名称:直接调用方法即可。
- 使用
fs.readdirSync(urlPath)方法 - 这里需要使用到同步方法,因为后面的第 12 行需要用到其返回值,防止
files.length为 0。
- 使用
- 获取该文件夹里的所有文件的修改日期:使用循环遍历获取到每一个文件的状态。
- 首先需要获取到每一个文件的在磁盘上的访问路径。需要使用到路径拼接,如第 14 行所示 。
- 然后调用
fs.statSync(per_file_url)来 获取到文件状态,如第 18 行所示 。 - 获取到 每个文件的修改日期,调用文件状态变量的
mtime属性即可,如第 21 行所示。 - 因为 获取到的日期是时间戳,所以需要包装成 Date 对象,如第 21 行所示。
- 将获取到的 Date 对象,格式化日期,这里只粗略地格式化,注意
getMonth()方法的值 要加一。 - 在读取文件中,会读到系统的自带文件,会抛出文件被使用以及文件不允许访问的异常,需要捕获到,否则会停止 js 运行。对于抛出异常的文件需要往修改时间里放入空内容,来进行对齐。
- 获取该文件夹里的相对位置:
files变量
} else if (stats.isDirectory()) {
// 如果是目录才读取模板网页目录列表
var templateStr = fs.readFileSync('./static-template.html').toString()
// 同步读文件目录
// 这里需要用到读取的结果所以需要同步
var files = fs.readdirSync(urlPath)
// 修改时间数组,与文件目录相对应
var update_date_array = []
for (var i = 0; i < files.length; i++) {
// 拼接目录里文件的访问路径
var per_file_url = path.join(wwwDir, urlPath, files[i])
try {
// 对目录里的每个文件读取其状态
var temp_stat = fs.statSync(per_file_url)
// 把获取到的时间戳包装成Date对象
var update_date = new Date(temp_stat.mtime)
// 格式化时间
update_date =
update_date.getFullYear() +
'年' +
(update_date.getMonth() + 1) +
'月' +
update_date.getDate() +
'日'
// 放进数组里
update_date_array.push(update_date)
} catch (error) {
// 这里会读到一些系统文件,会抛出异常,所以就把异常捕获到
// 放进空内容便于对齐
update_date_array.push('')
console.error(error.message)
}
}
// 渲染网页,传三个数据到网页
// 1. 目录里的每个文件名
// 2. 当前目录的位置
// 3. 目录里的每个文件的修改时间
var htmlStr = template.render(templateStr, {
files: files,
urlPath: urlPath,
array: update_date_array,
})
// 发送到客户端
res.end(htmlStr)
}
结果如下图:
2.8 服务端渲染和客户端渲染
服务端渲染:在服务器里生成了初始网页,再发送给客户端。
客户端渲染:服务器发送相应的数据到客户端,然后在客户端自己生成初始网页。
判断如何网页是服务端渲染还是客户端渲染的。
- 右键查看网页源代码,然后搜索某个商品的名称,如果存在则是服务端渲染。
- 在切换页面时,页面是否刷新,如果刷新了就是服务端渲染。
举一个京东的例子:
在京东搜索商品,这里搜索sony游戏机。
- 会看到处于第一页的商品,这些商品的信息是服务端渲染。因为在搜索时页面会刷新,而且查看源代码时,可以看到某个商品的名称,如下图所示。
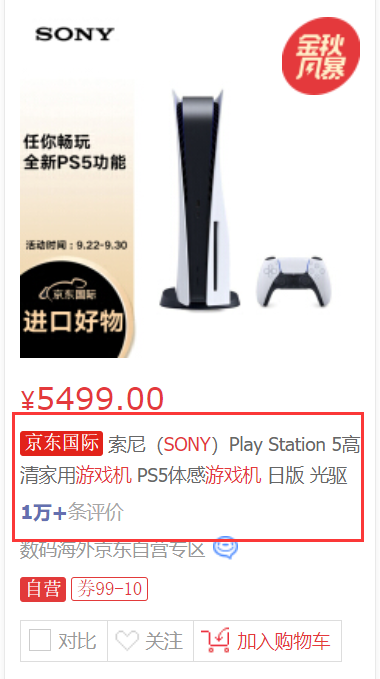
其中红色字体,使用了 font 标签来包裹。

- 然后跳转到后面几页,下面为页面中一个商品。

- 然后在源代码中搜索商品名字,发现无搜索结果。
2.9 静态资源
因为我们发送到客户端的只是经过模板网页渲染出来的初始网页,CSS 和 Javascript 都没有获取到。这时就需要再次向服务器发送静态资源请求。
而我们为了统一,会将资源放在本地服务器的 public 下。
这样我们可以约定一个规矩,只要你的请求链接是 public 开头的,就自动找到本地服务器中的 public 文件夹。
下面为代码示例:判断 url 的前面是否以 " /public/ " 开头,如果是则在本地里读取指定文件。
if(url.indexOf('/public/') === 0) {
fs.readFile('.' + url, function (err, data) {
if (err) {
return res.end('404 Not Found.')
}
res.end(data)
})
}
下面请求静态资源的状态码是 200,所以请求成功。

2.10 更新文件自动重启服务器
我们需要使用一个第三方命令行工具:nodemon。
- 安装:因为我们需要在不同的文件夹里使用,所以安装到全局里更方便。
npm install --global nodemon
- 安装完毕后 以管理员身份 打开 CMD 或者 PowerShell 运行以下代码:
# 之前的做法
node .\xxxx.js
# 现在的做法
nodemon .\xxxx.js
三、留言板雏形
接下来做出一个留言板雏形,单纯地跳转页面。
3.1 展示留言布局
布局很简单:两个使用了 bootstrap v5.0 的表格,再使用模板语言遍历输出表格内容。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.1/dist/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.1.1/dist/js/bootstrap.bundle.min.js"></script>
</head>
<body>
<div class="container">
<div class="row btn_leave_msg" id="btn_leave_msg">
<div class="col align-self-start">
<a href="/toLeaveMsg"><button type="button" class="btn btn-primary">发表留言</button></a>
</div>
</div>
<div class="row">
<table class="table table-hover">
<thead>
<tr>
<th scope="col">#</th>
<th>姓名</th>
<th>留言</th>
</tr>
</thead>
<tbody>
{{each msg_data}}
<tr>
<td>{{$index}}</td>
<td>{{$value['name']}}</td>
<td>{{$value['message']}}</td>
</tr>
{{/each}}
</tbody>
</table>
</div>
</div>
</body>
</html>
<style>
.btn_leave_msg {
margin-top: 50px;
}
</style>
3.2 留言页面布局
留言页面也很简单:两个 bootstrap v5.0 的文本框,然后外面套一层 form 表单用于提交数据,提交的请求是 /LeaveMsg。
这里只能使用 get 方式提交,post 方式之后会提到。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.1/dist/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.1.1/dist/js/bootstrap.bundle.min.js"></script>
</head>
<body>
<div class="container">
<form method="GET" action="/LeaveMsg">
<div class="row"><label for="basic-url" class="form-label">请输入你的姓名</label>
<div class="input-group mb-2" style="width:300px">
<input type="text" class="form-control" id="basic-url" aria-describedby="basic-addon3" name="name">
</div>
</div>
<div class="row"><label for="basic-url" class="form-label" >请输入你的留言</label>
<div class="input-group" style="width:600px">
<textarea class="form-control" aria-label="With textarea" name="message"></textarea>
</div>
</div>
<div class="row btn_leave_msg">
<div class="col align-self-start">
<button type="submit" class="btn btn-primary">发表留言</button>
</div>
</div>
</form>
</div>
</body>
</html>
<style>
.container {
margin-top: 50px;
}
.btn_leave_msg {
margin-top: 50px;
margin-bottom: 20px;
}
</style>
3.3 编写服务器代码
(1)走通主页
预备代码依然是老三样:引入包、指定服务器端口和开启服务器。
然后对 “ / ” 请求进行处理:读取数据,并将数据渲染到页面中。
if (url === '/') {
fs.readFile('./展示留言.html', 'utf8', function (err, data) {
if (err) {
return response.end('404 Not Found.')
}
var htmlStr = template.render(data.toString(), {
msg_data : msg_data
})
response.end(htmlStr)
})
}
(2)走通留言页面
走通留言页面很简单:判断请求、读取文件并发送到客户端。
if(url === '/toLeaveMsg'){
fs.readFile('./留言板.html', 'utf8', function (err, data) {
if (err) {
return response.end('404 Not Found.')
}
response.end(data.toString())
})
}
(3)实现留言功能
收到留言页面的请求并实现留言功能需要做几件事:
- 解析留言数据:
- 因为是 get 请求,所以请求的留言数据都在网址上,所以解析 url 即可。
- 如果新的
new URL()方法来解析,需要第二个参数——网址的origin部分,而request.url是没有的,所以需要在请求的头部中获取——request.headers.referer。 - 然后返回的是
URLSearchParams,使用 foreach 来遍历数据,将数据添加到数据中。
- 跳转页面
- 跳转页面需要先设置状态码——302;
- 然后设置响应头部的属性 Location:
- 重定向的状态码有两个:
- 301:永久重定向,代表源网站已被废弃。对于搜索引擎是优化,因为 302 就告诉了搜索引擎,源网站的内容已经不合适爬取。
- 302:临时重定向,只代表网页临时重定向到某个网页。会产生搜索引擎挟持。
- 搜索引擎挟持举一个例子:挟持人 A 在他的网站上重定向到了 被挟持人 B 的网站,而在搜索引擎中可能会显示 A 的网址,却是 B 网址的内容。
if(url.indexOf('/LeaveMsg') === 0){
// 获取到get请求的数据
var urlObj = new URL(url, request.headers.referer).searchParams
var tempObj = {}
// 遍历对象中的数据
urlObj.forEach(function(value, key){
tempObj[key] = value
})
// 将数据放置到全局变量中
msg_data.push(tempObj)
// 设置响应状态码
response.statusCode = 302
// 设置跳转的页面
response.setHeader('Location', '/')
response.end()
}
四、模块系统
使用 Node 编写应用程序主要就是在使用:
- EcamScript语言
- 和浏览器中的不同,在 Node 中没有 BOM 和 DOM。
- 核心模块
- 文件操作的 fs
- 网络服务的 http
- url 网址处理和解析模块
- path 处理文件和目录的路径模块
- os 操作系统模块
- 第三方模块
- art-template
- 必须通过 npm 来下载使用
- 自己编写的模块
4.1 什么是模块化
模块化主要几个特性:
- 文件作用域
- 通信规则
- 加载 require
- 导出 exports
而 CommonJS 为服务器提供了一种模块形式的优化。
- 有模块作用域
- 使用 require 方法来加载模块
- 使用 exports 接口对象用来导出模块中的成员
4.2 导出规则
我们可以选择文件中我们需要导出的对象。有单个导出和多个导出。
(1)单个导出
单个导出必须使用 module.export = 对象
(2)多个导出
多个导出使用可以使用 module.export.变量名 = 对象 或者 export.变量名 = 对象
4.3 导入规则
- 当导入模块的时候,会自动运行模块的全部代码。
- 当多次导入相同的模块,会自动在缓存里加载,不会再次运行模块的代码。
- 模块的引入路径有几种,核心模块、第三方模块和自己编写的模块。
- 核心模块和第三方模块:引入路径只填写模块名称。例如:
var http = require('http') - 自己编写的模块:引入路径填写 完整 的文件路径,例如:
var test = require('./test.js') - 而第三方模块的引入规则也是先在 node_module 文件夹里找出需要导入的模块名称,然后在里面的
package.json中找到 main 属性的属性值,一般为 js 文件,然后将其作为入口。如果没有 main 属性则默认找到index.js。 - 如果在当前的 node_module 文件夹里没有找到,就会找上一层的 node_module ,知道找到根目录为止。
- 核心模块和第三方模块:引入路径只填写模块名称。例如:
4.4 npm
npm ,node package manager,node 包管理工具。
(1)包说明文件
包说明文件,就像一个关于当前包的说明书,可以记录包的 github 仓库、包的名字以及包的入口。
例如下面 art-template 中的 package.json 文件。
- 第 1 ~ 5 行:
author——包的作者名字和邮箱。 - 第 6 ~ 8 行:
bugs——bugs 的提交地址。 - 第 9 ~ 18 行:
dependencies——使用包锁需要依赖。 - 第 19 行:
description——包的介绍。 - 第 20 ~ 32 行:
devDependencies——开发包所需要的依赖。 - 第 33 ~ 35 行:
engines——使用所需要的引擎,这里要求 Node 版本大于 1.0 - 第 36 行:
homepage——当前包的 Github 的主页 - 第 37 行:
license——当前包的开源许可证。 - 第 38 行:
main——当前包的入口文件。 - 第 39 行:
name——当前包的名字。 - 第 40 行:
version——当前包的版本。
{
"author": {
"name": "tangbin",
"email": "sugarpie.tang@gmail.com"
},
"bugs": {
"url": "https://github.com/aui/art-template/issues"
},
"dependencies": {
"acorn": "^5.0.3",
"escodegen": "^1.8.1",
"estraverse": "^4.2.0",
"html-minifier": "^3.4.3",
"is-keyword-js": "^1.0.3",
"js-tokens": "^3.0.1",
"merge-source-map": "^1.0.3",
"source-map": "^0.5.6"
},
"description": "JavaScript Template Engine",
"devDependencies": {
"babel-cli": "^6.26.0",
"babel-preset-env": "^1.7.0",
"coveralls": "^2.13.0",
"eslint": "^3.19.0",
"eslint-loader": "^1.7.1",
"eslint-plugin-prettier": "^2.6.2",
"istanbul": "^0.4.5",
"mocha": "^5.2.0",
"node-noop": "^1.0.0",
"prettier": "^1.14.2",
"webpack": "^3.0.0"
},
"engines": {
"node": ">= 1.0.0"
},
"homepage": "http://aui.github.com/art-template/",
"license": "MIT",
"main": "index.js",
"name": "art-template",
"version": "4.13.2"
}
而我们当前项目也可以当成一个包,或者说一个模块,所以也可以有 package.json 文件。
- 使用
npm init命令就可以让 node 自动生成该文件。 - 我们自己项目包说明文件中最关心的是
dependencies。- 一般我们拷贝项目、将项目上传到 Github 上都会忽略
node_modules文件夹。 - 因为
node_modules文件夹里面的东西过于多,过于大。 - 这时我们只需要有
package.json文件,然后联网再运行npm install命令,npm 就会自动下载dependencies里的内容。
- 一般我们拷贝项目、将项目上传到 Github 上都会忽略
- 在新版 npm 中会新增
package-lock.json文件,其文件的作用是:- 下载速度快了:
- 因为里面包含了
node_modules文件夹里的所有模块的信息,包括下载地址。 - 第一次安装时,npm 需要在安装一个模块后继续再找其所依赖的模块,不断递归。
- 而
package.json文件直接存储了所有模块的下载信息,直接读取当前文件即可。
- 因为里面包含了
- 锁定版本:
- 上面的第 10 行中
"acorn": "^5.0.3",版本号前面有一个^符号,其代表可以安装 5.0.3 版本以上。 - 但实际使用中,如果安装不一样的版本,可能会导致程序出问题,这时就需要记录你使用时所安装的版本。
- 就如下面的代码所示。第 2 行的版本号没有了
^符号,第 3 行就是下载地址。(复制到浏览器就可以单独下载)
- 上面的第 10 行中
- 下载速度快了:
"acorn": {
"version": "5.7.4",
"resolved": "https://registry.npmjs.org/acorn/-/acorn-5.7.4.tgz",
"integrity": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
},
(2)npm常用指令
npm 提供了命令行工具,用户可以使用其来对项目的包进行管理。
| 命令 | 缩写 | 说明 |
|---|---|---|
npm --version | npm -v | 查看当前 npm 版本 |
npm -help | npm -h | 查看根命令的帮助 |
npm 命令 -help | npm 命令 -h | 查看当前命令的帮助。 可以看到当前命令的别名、缩写以及可选项。 |
npm install | npm i | 安装当前项目的全部依赖 |
npm install 包名 | npm i 包名 | 安装指定的包 |
npm install --save 包名 | npm i -S 包名 | 安装指定的包并记录到 package.json 里 |
npm uninstall 包名 | npm un | 卸载指定的包 |
npm uninstall --save 包名 | npm un -S 包名 | 卸载指定的包并删除 package.json 中的记录 |
npm list | npm ls | 列出当前目录已经安装的包 |
(3)使用淘宝镜像
因为 npm 在国外,所说安装包时可能会比较慢,我们可以使用淘宝镜像。
淘宝镜像:是一个完整 npmjs.org 镜像,你可以用此代替官方版本(只读),同步频率目前为 10 分钟 。
【2021 年 10 月 20 日的网址:淘宝 NPM 镜像 (npmmirror.com)】
- 如何使用:
- 在命令行输入命令
npm install --global cnpm,在全局环境里安装,方便使用。 - 安装模块时,使用
cnpm 包名即可,与自动重启服务器命令类似,只需要将命令前面的第一个单词替换就可以。
- 在命令行输入命令
- 如果不想每次使用
cnpm下载,可以在npm命令中带参数,就可以通过淘宝服务器下载。npm install 包名 --registry=https://registry.npmmirror.com- 经常输入后面一大串字符不方便,可以将其添加到配置文件中。
- 修改配置文件:
npm config set registry https://registry.npmmirror.com